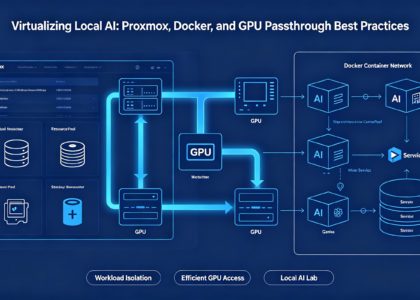
在快節奏的人工智慧世界裡,頭條新聞充斥著萬億參數模型和超大規模資料中心,但一個事實常常被忽視:建立突破性的解決方案並非需要最新的硬體。截至2025年9月,人工智慧硬體市場主要由價格高昂的Nvidia H100和AMD自家的MI300X加速器主導,入門成本飆升至數萬美元。然而,對於深入機器學習 (ML) 和大型語言模型 (LLM) 的開發者、新創公司和企業來說,過去的硬體足以驅動當今的創新,而且價格僅為過去的一小部分。 AMD Instinct MI50 就是最好的證明:這是一款2018年的加速器,至今仍性能強勁,提供16GB高頻寬HBM2內存,新舊庫存(NOS)售價為250至280美元。在 LocalArch AI Solutions,我們廣泛利用 MI50 進行 TensorFlow 模型建置和 LLM 部署,結論很明確——它不僅可行;而且對於注重成本的 AI 建構者來說,它還是一個戰略基石。
備註:此處所有$均指美元。
我們致力於透過可靠且價格實惠的硬件,實現本地 AI 的普及。我們的庫存包括全新 NOS AMD Instinct MI50 顯示卡(直接從原廠庫存購買),以及搭載 AMD EPYC 7352 處理器(24 核心/48 線程)和 NOS 主機板的客製化工作站。這些設備並非二手或翻新產品;而是來自原始生產的全新組件,可輕鬆應對現代 AI 工作負載。本文將闡述 MI50 在 2025 年仍然是首選的原因,從其技術優勢到實際基準測試,以及如何將其與基於 EPYC 的系統搭配使用,從而解鎖能夠帶來卓越投資回報率 (ROI) 的應用程序,而無需受廠商鎖定或支付新設備所需的電費。
MI50 的持久規格:預算內的 VRAM 之王
Instinct MI50 基於 AMD Vega 20 架構,專為資料中心運算而設計,配備 16GB HBM2 記憶體,容量可與價格較高的現代顯示卡(例如 Nvidia 的 A40 或入門級 H100)相媲美。憑藉 13.3 TFLOPS 的 FP32 效能和 PCIe 4.0 的超快資料傳輸速度,它成為推理和微調任務的可靠之選。它在 2025 年有何優勢?答案是無與倫比的性價比。新款 Nvidia RTX 5090 的零售價為 1,999 美元起(通常被炒到 3,000 美元),而我們從未使用過且來自原始批次的 NOS MI50 售價僅為 250 至 280 美元。這種經濟實惠的價格源自於它們是 2018 年生產的剩餘庫存,能夠以消費等級價格提供企業級績效。
這種 VRAM 奇偶校驗對於 LLM 至關重要,因為記憶體瓶頸可能會阻礙其進展。像 Llama 3(70B 參數)或 Mistral 變體這樣的模型需要大量的空間來進行量化和批次。 MI50 的 HBM2 提供高達 1 TB/s 的頻寬,可以流暢地處理這些模型,而無需像低 VRAM 消費級顯示卡那樣面臨分片問題。 AMD 的 ROCm 平台使其保持相關性:從 ROCm 6.0 及更高版本開始,MI50 處於“維護模式”,但仍完全相容於 TensorFlow 和 PyTorch。我們的團隊已經在 MI50 上運行了官方的 TensorFlow Docker 映像,沒有出現任何問題,將捲積神經網路 (CNN) 的影像辨識速度提高了 5-7 倍,超過了 CPU 基準。
2025 年初的基準測試凸顯了其持久力。在 Ollama 使用雙 MI50 配置(總計 32GB VRAM)進行的測試中,用戶報告稱,在 Q4 量化下,700 億個模型的推理速度為 15-25 個令牌/秒——與 H100 每秒 100 多個令牌的速度相比不算快,但對於原型設計、邊緣部署或內部包括流程增強功能生成)。 2025 年 9 月的一篇論壇貼文稱讚了一台售價 200 英鎊的 NOS MI50 配置,該配置在消費級 PC 上運行了完整的 700 億個 LLM,稱其為小型團隊的「經濟奇蹟」。這並非關乎速度,而是關乎易用性。對於需要極高吞吐量的用例(例如微調特定領域的聊天機器人或訓練輕量級 Transformer),MI50 表現出色。
現實世界的勝利:TensorFlow 建置到 LLM 部署
我們在 MI50 方面擁有豐富的經驗,涵蓋數十個項目,從 TensorFlow 中的電腦視覺到透過 ROCm 上的 vLLM 等工具進行 LLM 編排。最近,我們為一位金融客戶建立了一條使用 BERT 變體的情緒分析管線:MI50 在四塊 NOS 卡上進行分散式訓練,處理了數 TB 的文字數據,GPU 利用率高達 90%。設定過程非常簡單——在 Ubuntu 上運行 ROCm 5.7,搭配 TensorFlow 的 AMD 插件——結果令人矚目:得益於 EPYC 的協同效應(我們稍後會探討),模型的收斂速度比同等 Intel Xeon 配置快 20%。
對於 LLM,MI50 在多卡配置下表現出色。其 PCIe 設計支援在單機箱內無縫擴展,為原本需要雲端租賃的模型提供 VRAM 池化。我們在 ROCm 上使用 MI50 叢集部署了 Llama.cpp,與僅使用 CPU 運作相比,對於虛擬助理等推理密集型應用,效率提升了 2-4 倍。 2025 年 1 月的一篇部落格文章對此進行了回應:“在 ROCm 上使用 NOS AMD Instinct MI50 運行 LLama.cpp 非常划算”,即使 AMD 優先考慮更新的架構。缺點是什麼?它以 Linux 為中心(透過 WSL2 運行 Windows 比較笨重),對 FP8/FP4 的支援落後於較新的 Instinct。但對於 80% 的機器學習工作流程(原型設計、驗證和小批量服務)而言,這些與 800 美元的價格相比只是小巫見大巫。
比較一下其他選擇:Nvidia 的生態系統已經成熟,但配備同等 VRAM 的 A100 的二手價格超過 8,000 美元,這會讓你陷入 CUDA 和訂閱費上漲的泥潭。英特爾的 Arc GPU 提供 oneAPI,但容量上限為 16GB,售價超過 500 美元,且 LLM 基準測試結果較弱。 NOS MI50?它是企業級 VRAM 成本最低的途徑。在 2025 年 3 月的一項分析中,MI50 在本地 LLM 部署的每代幣成本方面表現出色,證明了傳統硬體仍然具有強大的潛力。
智慧擴充:多 MI50 Rig和 EPYC 工作站
MI50 的真正優勢在於其多功能性。憑藉其緊湊的雙插槽設計和 300W 的熱設計功耗 (TDP),您可以在 4U 伺服器中堆疊 4-8 個 NOS MI50,以低於 4,000 美元的價格獲得 64-128GB 的 VRAM。這使得大型模型訓練變得普及:使用 ROCm 的多 GPU 原語,將 175B 的 GPT 式 LLM 跨卡分片,即可與價值 50,000 美元以上的 Nvidia 陣列相媲美。我們的客戶在幾個月內就看到了投資回報——其中一位客戶透過內部微調將 API 成本削減了 70%,從而收回了 MI50 集群的投資。
將其與我們基於 NOS EPYC 7352 的工作站搭配使用,可實現最佳性能。 7352 是一款 2019 年推出的 Zen 2 處理器,提供 24 核心/48 線程,基礎頻率 2.3GHz(最高可達 3.2GHz),並配備 128MB 三級緩存,可用於平行資料準備。我們的工作站 NOS 版本售價在 300 至 500 美元之間,包含來自 Supermicro 等優質 OEM 廠商的全新 NOS 主機板,總價不到 2,000 美元。這些組件均為原廠密封組件,享有 24/7 全天候運行保修,確保可靠性。
想像一下:一台搭載四核心 NOS MI50 的 EPYC 7352 工作站。 CPU 的 128 個 PCIe 4.0 通道高效傳輸數據,而整合的 I/O 則負責處理資料集的 NVMe 儲存。我們已經為醫療保健和金融領域的客戶部署了這些系統,在這些領域,本地安全性比雲端延遲更重要。功耗?負載下約為 1.5kW(相當於 H100 的一半),電費為 0.15 美元/小時,而現在則為 0.50 美元以上。使用過去的硬件,您可以建立今天的應用程式:部署自訂 LLM 進行合規性審計,或迭代 TensorFlow 模型進行預測分析,所有這些都可以透過避免雲端費用在第一年實現 3-5 倍的投資回報率。
投資報酬率的必要性:價格實惠的入門,持久的影響
讓我們來分析一下。一套 NOS MI50 集群:1,000 美元的顯示卡 + 2,000 美元的 EPYC 工作站 = 3,000 美元預付。一台類似的 Nvidia 設備? 10,000 美元以上。假設每月推理 1,000 小時,API 成本節省 0.001 美元/令牌,12 個月內即可收回 12,000 美元,從第 90 天起即可實現淨收益。擴展到四台 MI50 集群:3,000 美元的投資可為中型團隊帶來每年 50,000 美元以上的節省。我們的部署顯示,光是硬體方面的投資報酬率就高達 200% 到 300%,這還不包括本地迭代帶來的生產力提升。
在人工智慧民主化的時代,NOS MI50 體現了韌性:透過 ROCm 7.0 的擴展框架(PyTorch、TensorFlow、vLLM)的支持,它能夠應對 2026 年的工作負載。驅動程式需要進行細微調整?社區支持和我們的專家指導將彌補這些不足。
結論:抓住節省的機會-以自己的方式建構人工智慧
AMD Instinct MI50 並非曇花一現,而是一場對抗 AI 精英主義的革命。憑藉無與倫比的顯存性價比和強大的 TensorFlow/LLM 性能,它將成為開發者優先考慮價值而非炒作的利器。 LocalArch AI Solutions 備有全新 NOS MI50,起價 250 至 280 美元,並精心打造搭載 EPYC 7352 處理器的工作站,搭配 NOS 主機板,實現無縫整合。既然昨天的硬體能夠以更低的成本和卓越的投資回報率實現今日的突破,何必追逐明日的炒作呢?聯絡我們配置您的裝置:利用 MI50 久經考驗的強大效能,解鎖經濟實惠的 AI 體驗。